Extraction confidence
Every field carries the confidence behind it
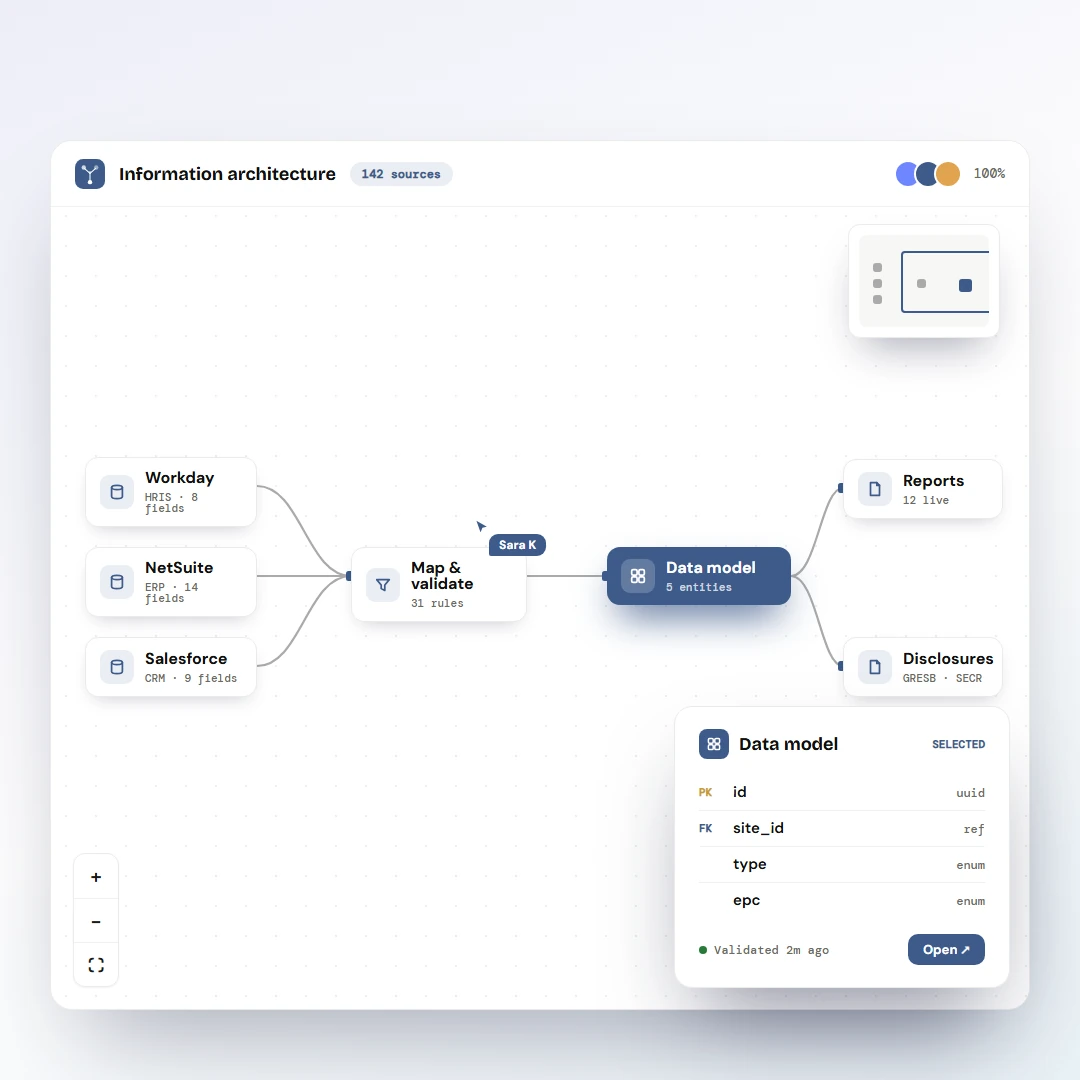
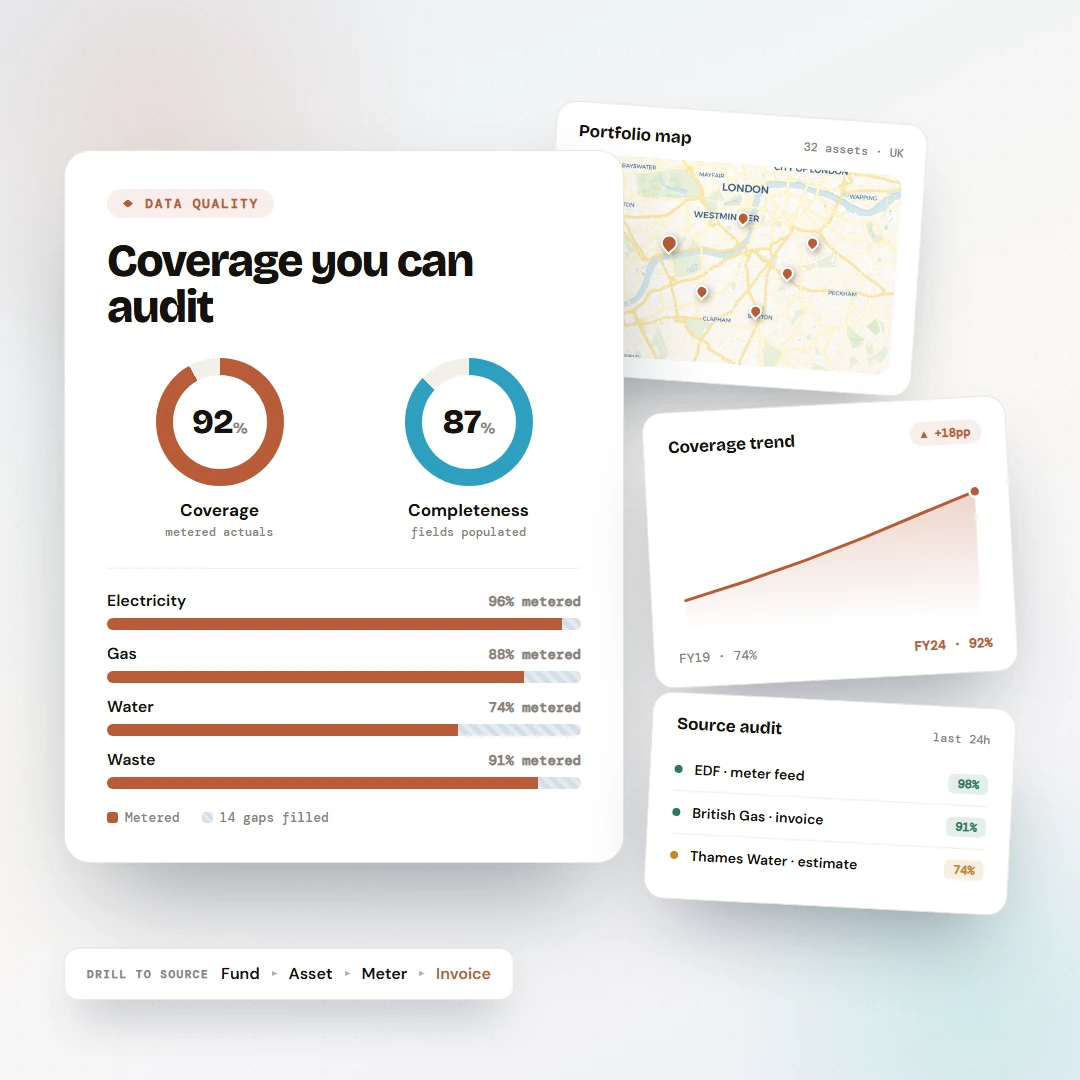
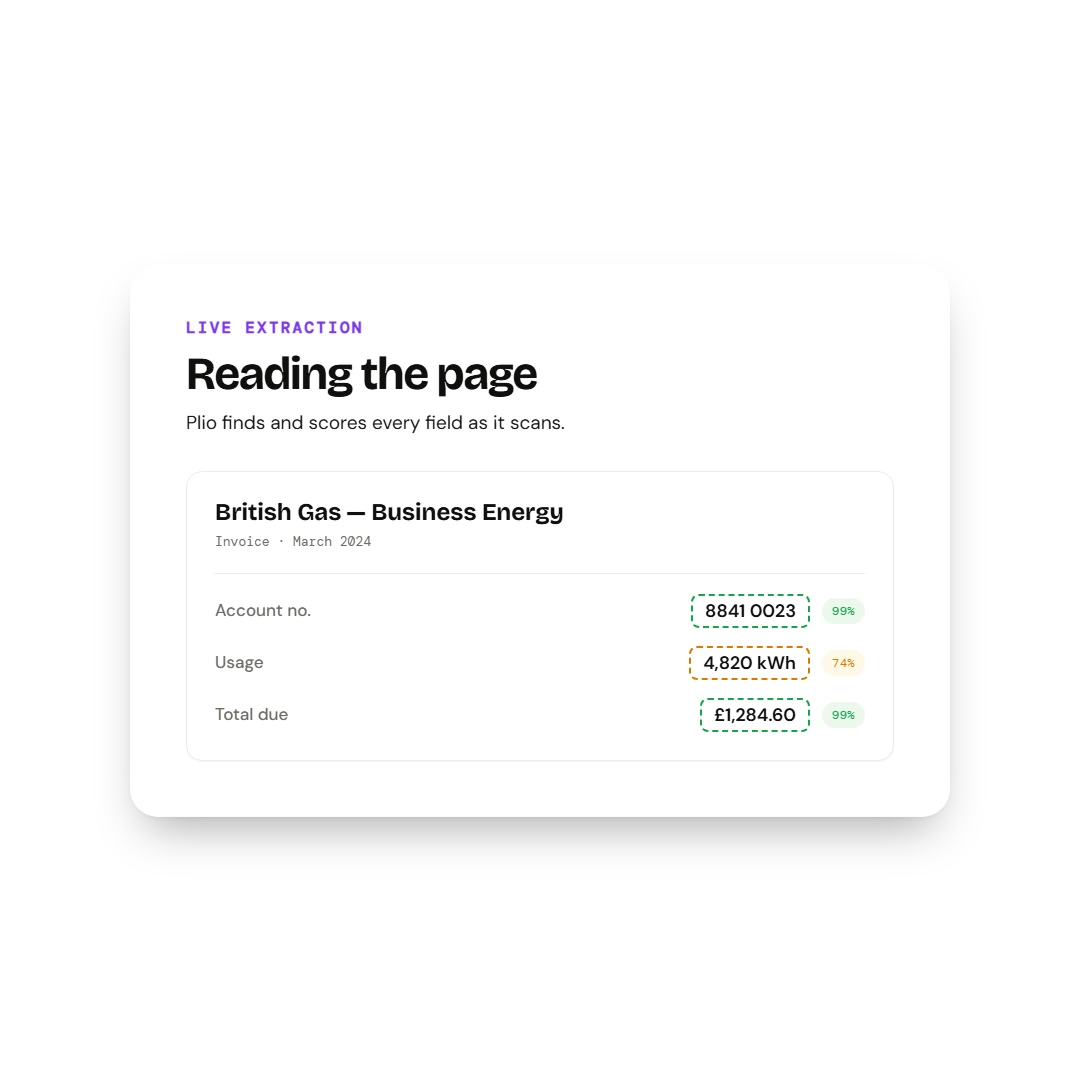
Each extracted value sits next to a confidence score and the rule that produced it. The page reads as a document the user can audit, not a black box.
1
2
3
Northern Power Ltd12 Trinity Way · Leeds LS1 4DJ
INVOICENP-2025-04-1283
Billing period
01 Mar – 31 Mar 2025
Charges
Energy supply (18,420 kWh @ 0.142)2,615.64
Standing charge (31 days)14.88
Climate change levy76.84
VAT?-
Total due£2,847.92
Extracted fields
6 of 7
Vendor
Northern Power Ltd
99%High
Invoice no.
NP-2025-04-1283
97%High
Period
01 Mar – 31 Mar 2025
94%High
Total kWh
18,420
86%High
Total amount
£2,847.92
81%Low
VAT %
- not found
0%Failed
4 auto · 1 review · 1 manualrouted
What you’re looking at
1
Three-tier confidence. High (≥90%) lands silently. Low (70–89%) routes to review. Failed (<70% or empty) routes to manual.
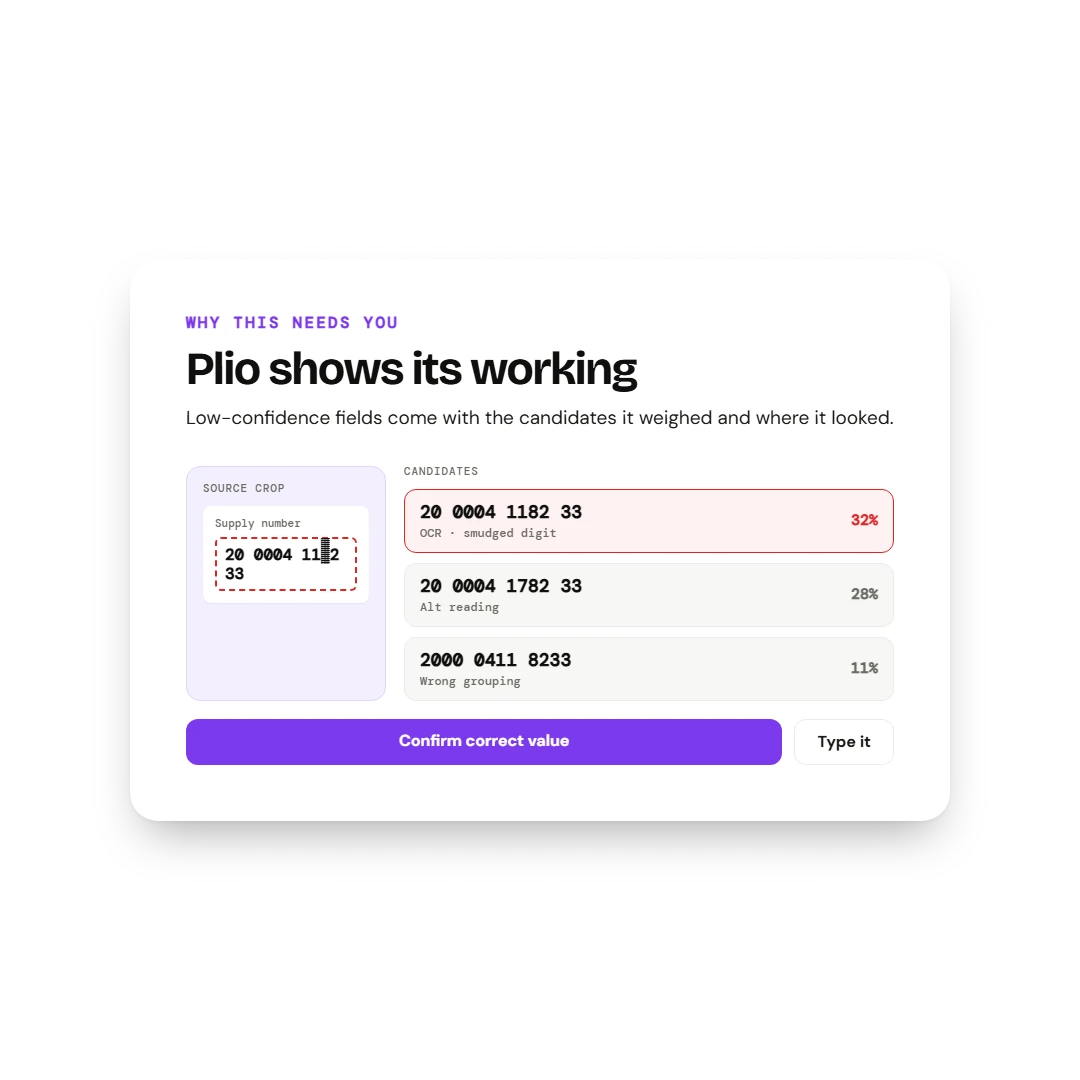
2
Provenance per field. Hover any field and the source rule + the original character range in the invoice surface together.
3
Failures are first-class. A red or empty field is a designed state, not an error. The number on the report can survive a question from finance.