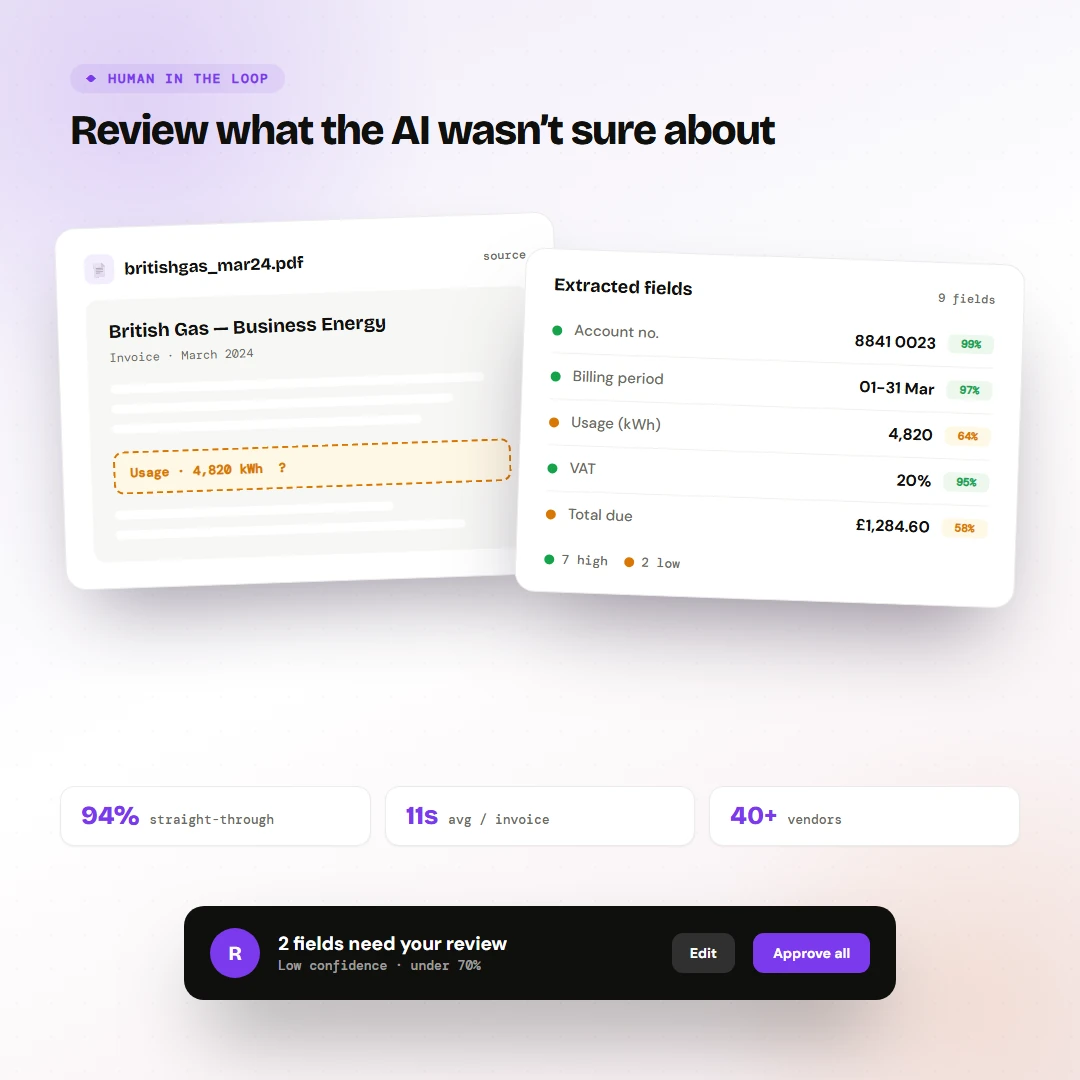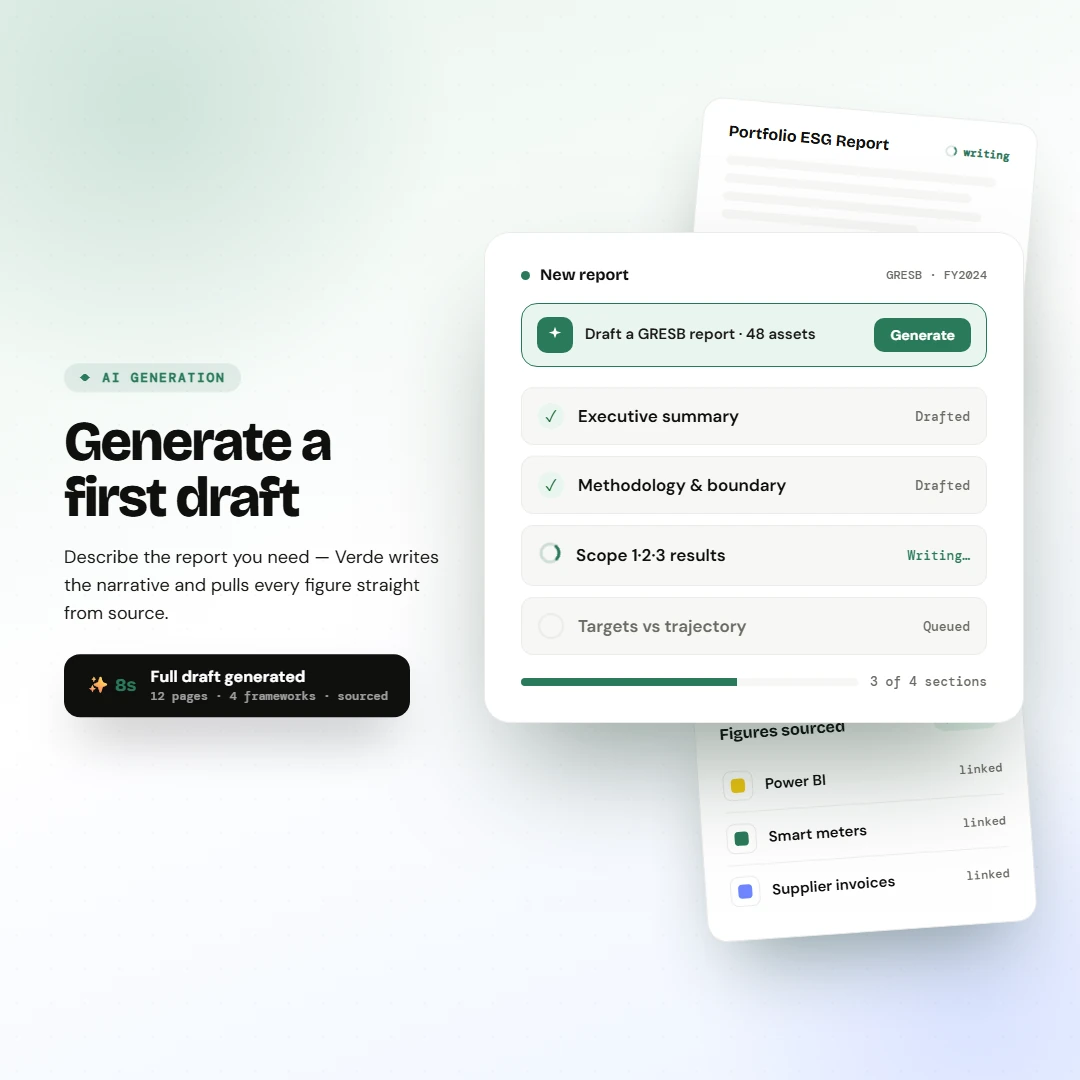
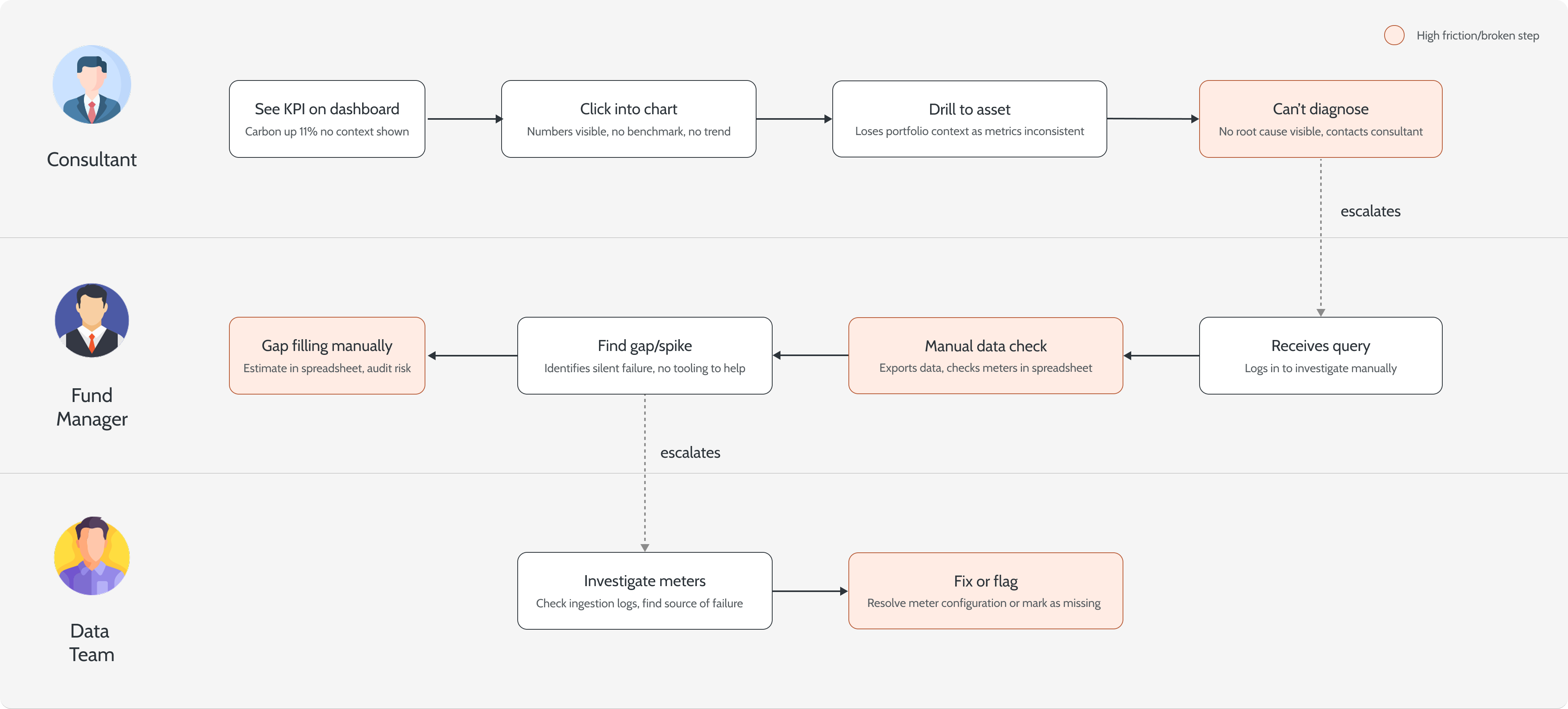
Drill-down
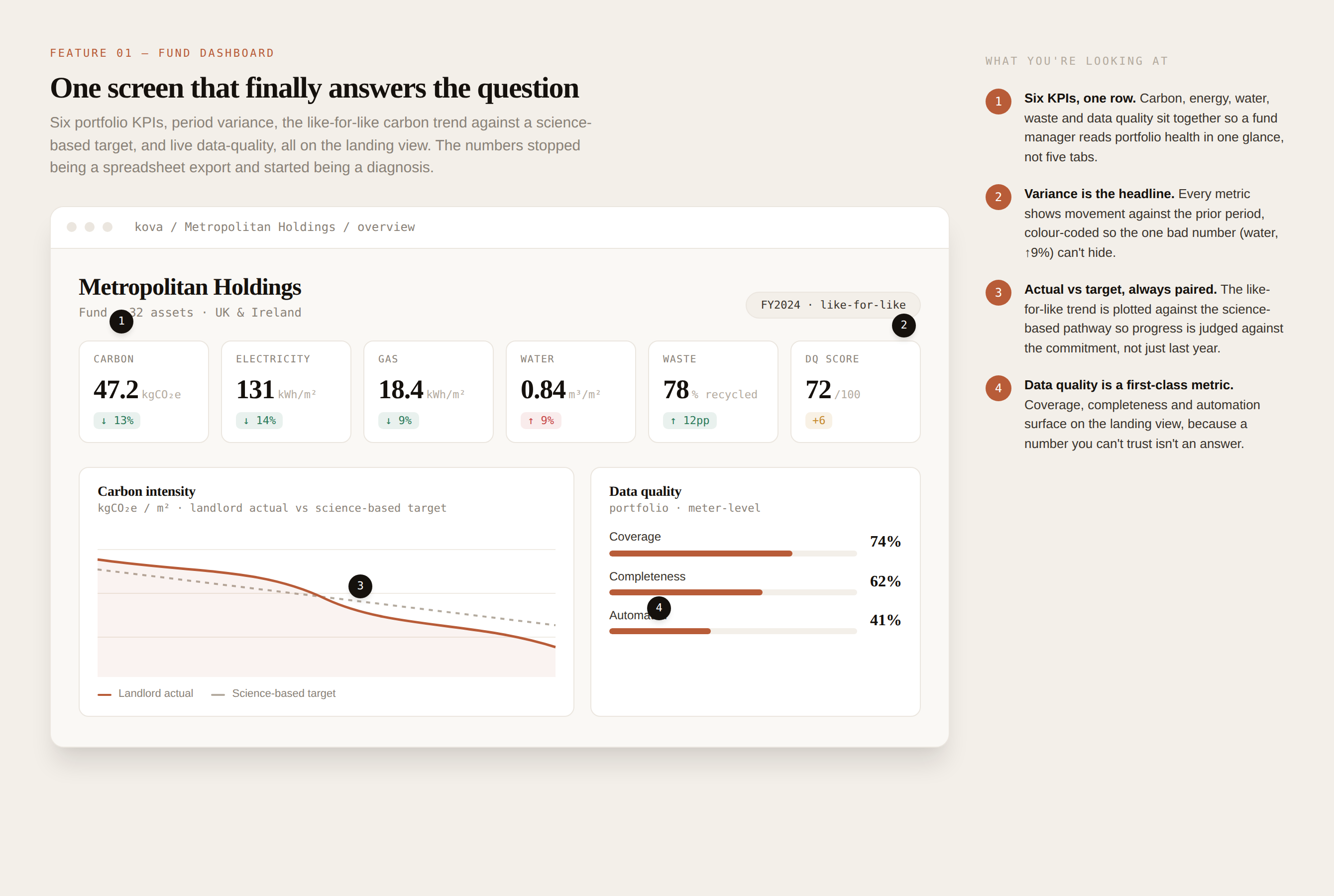
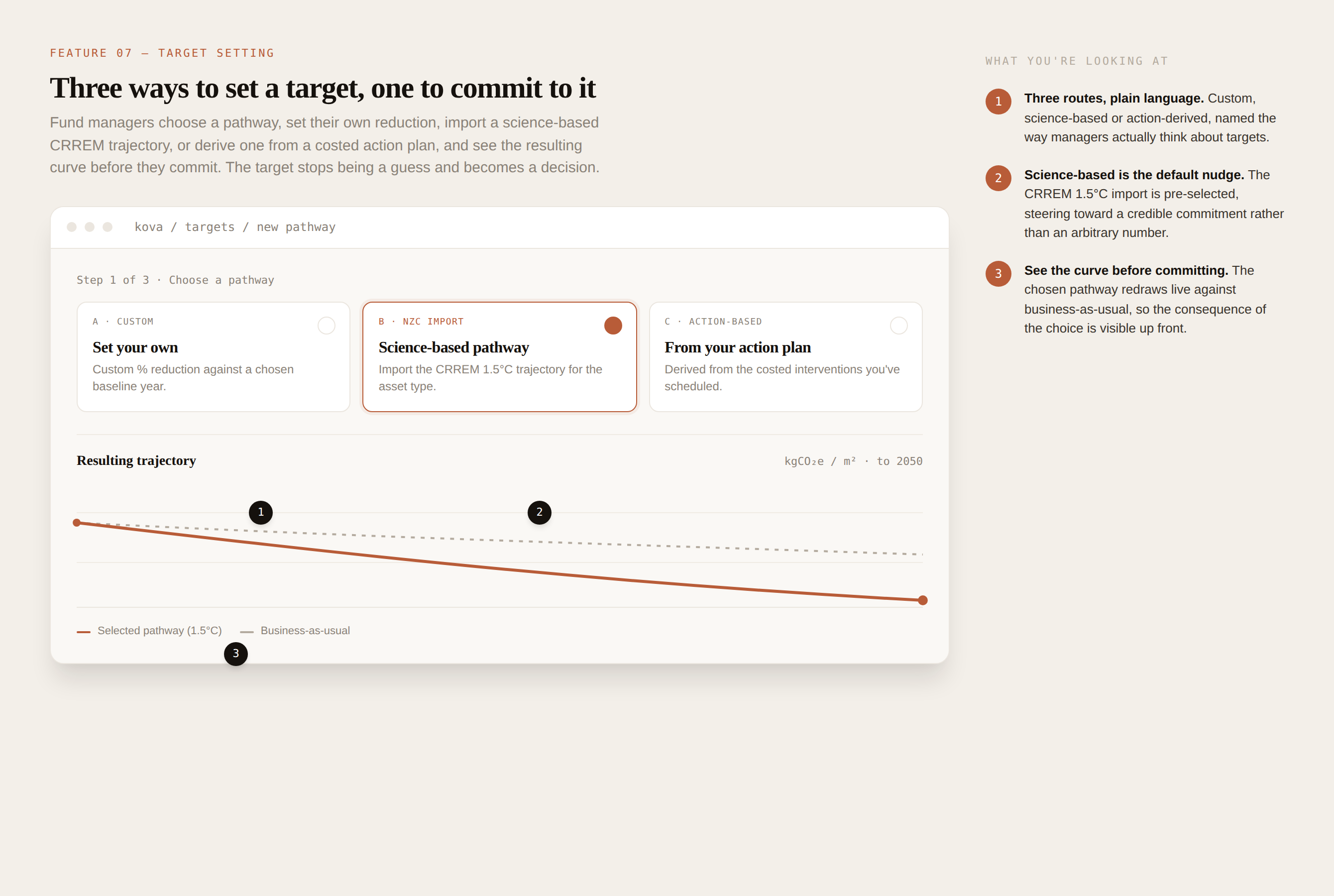
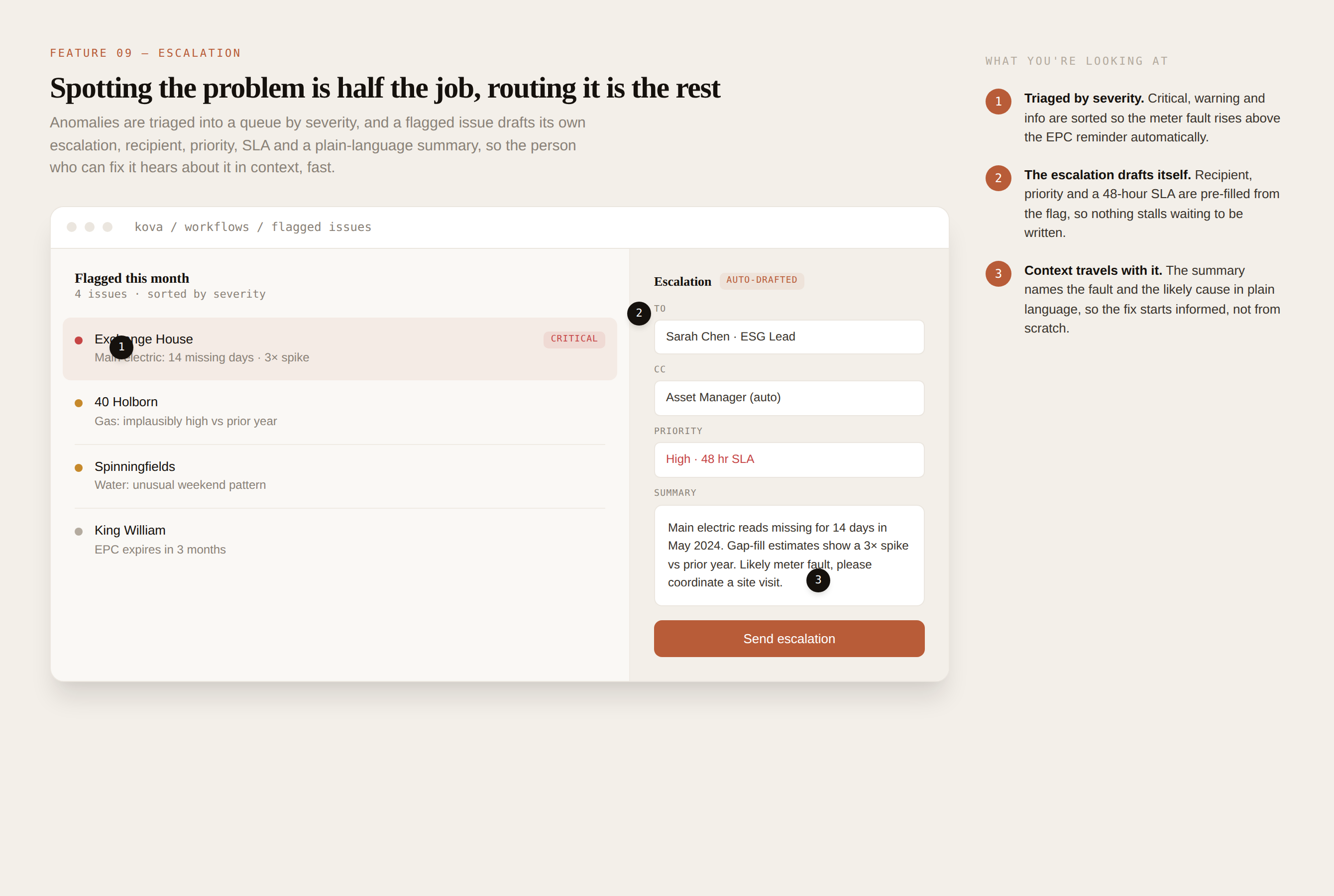
Spot it, trace it, fix it, in three clicks
From a healthy fund to the single asset dragging it down to the exact missing meter readings behind the anomaly. The hierarchy lets a manager move from "something's off" to "here's the cause" without leaving the screen.
1
2
3
L1 · FUND
Metropolitan Holdings
Fund · 32 assets
Carbon
47.2
↓ 13%
DQ
72
+6
→
L2 · ASSET
Exchange House
London EC2 · 18,400 m²
Carbon
62.1
↑ 47%
Coverage
38%
low
→
L3 · METER
Main electric
kWh · last 30 days
14 gaps · flagged as gap-fill candidates
What you're looking at
1
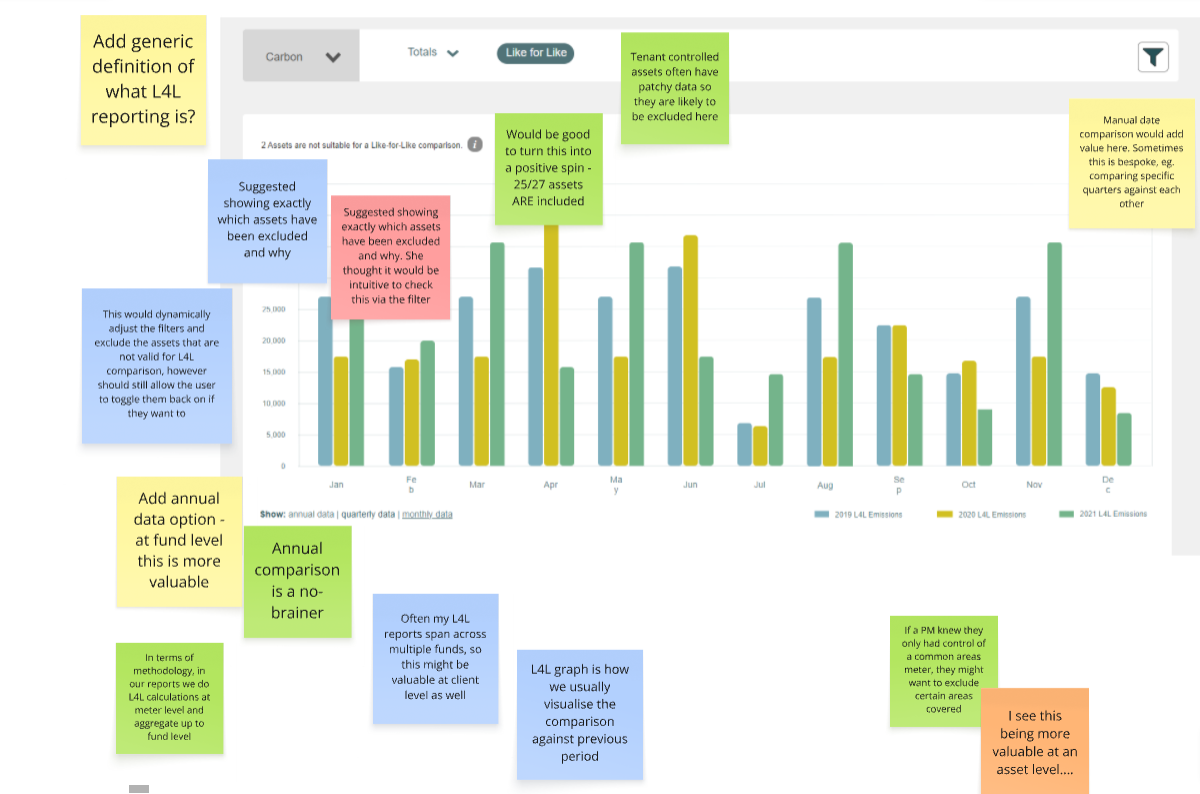
Healthy at the top. The fund reads well, carbon down 13%, DQ trending up. Nothing here says there's a problem.
2
One asset breaks the pattern. Exchange House shows carbon up 47% on just 38% coverage, the anomaly hiding inside the fund average.
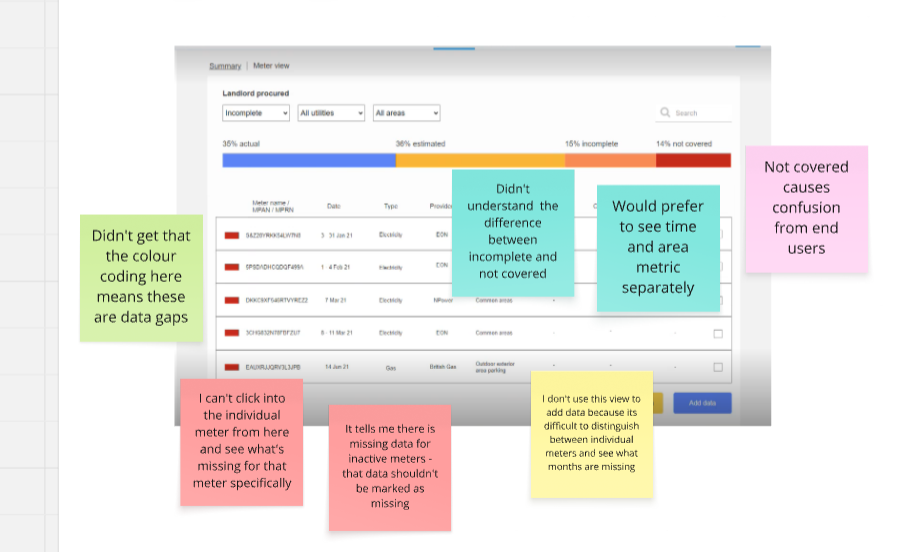
3
Down to the cause. The meter view exposes 14 missing readings, the real reason the number looked wrong, ready to gap-fill.